- 1024 (26일차)- sql 6일2023년 10월 24일 17시 35분 57초에 업로드 된 글입니다.작성자: 삶은고구마
TOP-N
-특정 컬럼 값 기준으로 가장 크거나/작은 n개의 값을 질의
ex)급여를 제일 많이 받는 사원 5명 조회, 이번 달 가장 많이 팔린 상품 3가지 조회 등등.
rowid
-테이블 특정 레코드(행)을 가리키는 논리적 주소값
(진짜 주소값은 아니고 해시코드와 비슷한 식별값이라 생각하면 될 듯)
select rowid, e.* from employee e where rowid = 'AAAStAAAHAAAAFjAAA'; --이렇게 쓸 일은 많지 않다.★rownum
-각 행에 대한 순서(번호)
-result set이 만들어질 때 순서대로 부여됨. 임의로 변경 불가(only read)
-인라인뷰, 또는 where절 사용시 새로 부여됨.
select rownum, e.* from employee e where dept_code = 'D5'; --만약 여기서 where절로 다시 result set을 갱신할 때 순서가 새로 부여됨
rownum 실습문제 - 급여 top5 조회
더보기1.일단은 급여 내림차순으로 결과를 확인하고.. select emp_name, salary from employee order by salary desc; ---- from( select rownum, emp_name, salary from employee where rownum between 1 and 5 --그냥 1에서 5번을 자른것이지 순위와 무관 order by salary desc ) ------------위의 과정을 통해 수정------------------ select rownum, e.* from( select --rownum, emp_name, salary from employee e order by salary desc ) e --인라인뷰때 새로 rownum이 부여됨 where rownum between 1 and 5;rownum 실습문제 - offset이 있는 랭킹 구하기
-급여 Top-n 6위~10위
더보기select * from( select rownum rnum, e.* from( select emp_name, salary from employee order by salary desc )e ) where rnum between 6 and 10;-rownum은 from,where절이 끝난 이후 완벽히 부여된다.
-where절에서 1부터 순차적인 접근은 허용.
-offset이 있는 경우 inlineview를 한 번 더 사용해야한다.
빨강박스
: 급여순위를 정렬
파란박스
:급여 순으로 1~10위를 매긴 rownum을 부여
초록박스
:순위 부여가 종료된 rownum을 1위가 아닌 6위부터 resultset에 포함
여기서 rnum이 아닌 rownum을 사용하면 2중 인라인뷰를 사용할 이유가 없어짐;
with
서브쿼리의 이름을 붙여 하위에서 참조하는 문법
예제 - 입사일순 top5
with emp_by_hire_date as( select emp_name, hire_date from employee order by hire_date )--as 소괄호 생략 불가 select * from emp_by_hire_date where rownum between 1 and 10;
예제 - 급여순위 6~10위
with emp_by_salary as( select rownum rnum, e.* from( select emp_name, salary from employee order by salary desc )e ) select * from emp_by_salary where rnum between 6 and 10;
WINDOW FUNCTION
-행과 행간의 관계를 쉽게 정의해주는 sql 표준함수
-os와는 관계없다.
-select절에서만 사용 가능
-순위, 집계, 순서, 비율, 통계 관련 함수 지원
1026
max() keep(), min() keep()
ex)
max(salary) keep(dense_rank first order by hire_date)
가장 최근에 입사한 사원
윈도우 함수 (arguments) Over ([partition by 절][order by절][windowing절])
args: 윈도우 함수의 인자로, 0~n개의 컬럼을 제공한다.
over절 : 행 그룹핑, 순서, 대상행 등을 지정
over 절 종류 설명 partition by 윈도우 함수의 group by order by 순서(select 의 그것) windowing 대상행을 지정 순위 관련 윈도우 함수
종류 설명 rank() over() 행간의 순위를 지정, 중복된 값이 있는 경우 그 다음 순위는 건너 뛴다 
dense_rank() over() 행간의 순위를 지정. 중복된 값이 있어도 순위를 건너뛰지 않음 
row_number() over() 행간의 순위를 지정. 중복된 값이 있어도 고유한 순위를 부여함.
row number는 같은 순위가 없다. 무조건 다른 순위를 매김
만약 200만원을 받는 두명에게 특정 기준으로도 order by를 할 수 있음
row_number() over(order by salary desc, emp_name) salary_rank
집계 함수
-일반 그룹함수와 동일한 이름으로 윈도우함수 지원.
-그룹함수 결과를 일반컬럼과 동시에 조회 가능종류 설명 sum() over() 합계 avg() over() 평균 count() over() 갯수 min() over() 최소 max() over() 최대 select emp_name, salary, floor(avg(salary) over()) "전체급여평균", salary - floor(avg(salary) over()) "평균과의 차이", count(*) over() "전체사원수", min(salary) over() "최소급여", max(salary) over() "최대급여" from employee;
비율 함수
-전체 합 중, 차지하는 비율 반환
-ratio_to_report() over()-오라클 전용
select emp_name, salary, round(ratio_to_report(salary) over(),2) "급여 총합 대비 비율ver1" --0.11 즉,11퍼 ,round(salary / sum(salary) over(),2) "급여 총합 대비 비율ver2" from employee;
선동일의 0.11은 11퍼를 의미한다.
DML(Data Manipulation Language)
-데이터 조작어
-테이블 데이터에 대해 CRUD 명령어
-Create,Read,Update,Delete 데이터에 대한 생성/조회/수정/삭제
-insert
-select(dql)
-update
-delete1)INSERT
-테이블에 데이터를 추가하는 명령
-행 단위 작성, 명령에 성공했다면, 테이블 행이 증가한다.
-문법이 두가지 있다.
문법1.insert into 테이블명 values (컬럼값1,컬럼값2, ...)
테이블 선언된 구조와 같이 순서, 갯수에 맞춰 모두 작성..
문법2.insert into 테이블명 (컬럼명1,컬럼명2, ..) values (컬럼값1,컬럼값2, ...)
데이터를 추가할 컬럼만 작성이 가능하다.
이때 생략된 컬럼은 기본값으로 처리가 된다.(기본값이 지정되지 않은 not null 컬럼은 생략 할 수 없다.)
생략가능한 컬럼: nullable 컬럼, 기본값 지정이 된 not null 컬럼
생략불가한 컬럼: 기본값 지정이 안된 not null 컬럼=>만약 컬럼 내용이나 갯수가 바뀐다고 한다면 문법2를 사용하는것이 효율적이다..
insert into sample (c) values ('고구마칩'); insert into sample (a,b) values (789, '테스트'); --RA-01400: NULL을 ("SH"."SAMPLE"."C") 안에 삽입할 수 없습니다 insert into sample (c,b,a) values ('ccc','bbb',999);--문법1로 함지민 추가 insert into employee_ex values ('301','함지민', '781020-2123453', 'hamham@kh.or.kr','01012343334', 'D1', 'J4', 'S3',4300000,0.2,200,default, default, default); --문법2로 장채현 추가 insert into employee_ex (컬럼명) values(컬럼값); insert into employee_ex (emp_id, emp_name, emp_no, email, phone, dept_code, job_code, sal_level, salary, manager_id)--, hire_date, quit_date ,quit_yn) values('302','장채현','901123-1080503','jang_ch@kh.or.kr','01033334444','
dml은 커밋을 해야 db에 반영이 된다. Data Migration
기존 데이터를 다른 테이블로 이전하거나 ,합치는 작업을 지원하는 insert문이 있다.
--subquery를 이용한 insert --사원 간단보기 테이블 생성 create table emp_simple( emp_id varchar2(3), emp_name varchar2(50), job_name varchar2(50), dept_title varchar2(50) ); insert into emp_simple ( select emp_id, emp_name, (select job_name from job where job_code = e.job_code) job_name, (select dept_title from department where dept_id = e.dept_code) dept_title from employee e ); select * from emp_simple; --insert all --두개이상의 테이블에 데이터 이전 시 적합 --1.입사일을 관리하는 사원 테이블 emp_hire_date --2.사원과 관리자 정보를 확인하는 테이블 emp_manager --반대로 두개의 테이블을 하나로 합치는 것도 있음 merge(있다는 것만 알아두기) --테이블 생성 시 기존 테이블 구조만 복사 (데이터는 추가 안함!) create table emp_hire_date as select emp_id,emp_name,hire_date from employee where 1= 2; --where절 조건이 false이기 때문에 컬럼만 생성되고 데이터는 들어가지 않는다.. select * from emp_hire_date; create table emp_manager as select emp_id,emp_name,manager_id, emp_name "MANAGER_NAME" --관리자 이름을 가져오고싶지만 원 테이블에 이런 컬럼이 없기때문에 애칭만붙임 from employee where 1= 2; select * from emp_manager; --단 manager가 없는 사원도 있기 때문에 not null을 수정해야함! desc emp_manager; alter table emp_manager modify manager_name null; -------------------------------------------------------------------- --기존 employee 데이터를 emp_hire_date, emp_manager로 각각 이전 insert all into emp_hire_date values (emp_id, emp_name, hire_date) into emp_manager values (emp_id, emp_name, manager_id, manager_name) select e.*, (select emp_name from employee where emp_id = e.manager_id) manager_name from employee e;2)UPDATE
-테이블 데이터(행 단위)를 수정
-where 절에 지정된 행의 컬럼 값을 수정.
-where 절이 지정되지 않는다면 모든 행의 컬럼값을 수정..-꼭 where절로 수정할 특정 행을 지정해줘야한다.
update 테이블명 set 컬럼명 where 수정할 행의 pk -- update employee_ex set dept_code = 'D1', --컬럼명 = 컬럼값 , 컬럼명 = 컬럼값 .... job_code='J3' where emp_id = '301';update 예제
임시환 사원의 직급 과장, 부서를 해외 영업 3부로 변경한다. (서브쿼리)
변경전: d2, j4 - 변경후 d7,d5update employee_ex set job_code = (select job_code from job where job_name = '과장'), dept_code = (select dept_id from department where dept_title = '해외영업3부') where emp_name ='임시환' and emp_id = '219';2)DELETE
-테이블의 행을 삭제하는 명령어..
-성공시 행의 수가 줄어든다.
-where 절을 사용하지 않으면 모든 행이 삭제 된다..-작업 후에 commit 이나 rollback으로 DB에 반영하기.
delete from employee_ex where emp_name = '장채현';
그 외..
TRUNCATE
-테이블 전체 행을 잘라내는(삭제) DDL
-실행 즉시 DB에 반영, 취소 불가능 (rollback해도 복원 안됨..)
-실행속도가 빠름.(dml 처리시 before image 작업이 없다.)
-즉, ddl은 커밋없이 실시간 반영/ dml은 commit해야 반영.
-create table도 commit이 되는거라 그 사이에 dml 작업시 주의할 것.
-ddl 실행 시, 해당 세션의 모든 작업내용은 함께 커밋됨.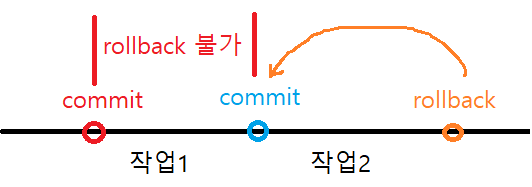
rollback은 undo 개념이 아님.
마지막 커밋 시점으로 되돌아간다.
특히, dml과 ddl을 혼용할 경우 create table도 commit이 되는 시점이라 주의 해야한다.
ddl을 사용하기 전에 커밋을 잘 해두기.
'공부 > 학습' 카테고리의 다른 글
1031 jdbc - day2 (0) 2023.10.31 1030 jdbc -day1 (0) 2023.10.30 1027 (29일차) - sql 9일차 (0) 2023.10.27 1026 (28일차) -sql 8일 (0) 2023.10.26 1023 (25일차)- sql 5일 (1) 2023.10.23 이전글이 없습니다.댓글